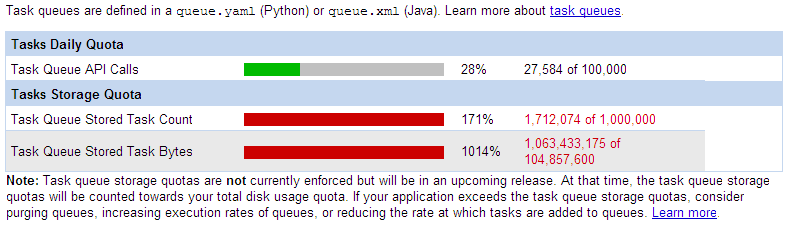
データベースについては基本的にサポート外とさせていただきます。とのことで詳細わからず、やってみてできたことだけ、書いておこうと思った次第。
詳しい知識がある方のみご利用ください。
ロリポップでの設定
ロリポップにログインして、ユーザー専用ページで「WEB ツール>データベース」を開く。 「データベース作成」ボタンを押す。
次の画面で、データベースのサーバーを選択、データベース名、パスワードを入力して「作成」ボタンを押す。

すると、こんな画面になって、ロリポップ管理画面での作業はおしまい。管理ツール phpMyAdmin を使って、テーブルとかをここで作ってしまうのもありかと。

Perl プログラム
あとは、サーバー上の Perl プログラムの書き方。参考にしたのはこちら。 で、例えば既存の list テーブルに一行挿入するプログラムがこちら。
use DBI;
$db = DBI->connect('DBI:mysql:LA00000000-abcdefghijkl:mysql504.phy.lolipop.jp', 'LA00000000', '1234567890123456');
$sth = $db->prepare("INSERT INTO list VALUES (1,'1st','memo 1st')");
$sth->execute;
$sth->finish;
$db->disconnect;
$db = DBI->connect('DBI:mysql:LA00000000-abcdefghijkl:mysql504.phy.lolipop.jp', 'LA00000000', '1234567890123456');
$sth = $db->prepare("INSERT INTO list VALUES (1,'1st','memo 1st')");
$sth->execute;
$sth->finish;
$db->disconnect;
赤はデータベース名、青はデータベースのサーバー名、緑はユーザー名、紫はパスワード。それぞれ、先ほどロリポップのデータベース作成で設定した値を使用。
もひとつ、list テーブルから id、name、memo を取得して表示するプログラムがこちら。
use DBI;
$db = DBI->connect('DBI:mysql:LA00000000-abcdefghijkl:mysql504.phy.lolipop.jp', 'LA00000000', '1234567890123456');
$sth = $db->prepare("SELECT id, name, memo FROM list");
$sth->execute;
$num_rows = $sth->rows;
print "該当 $num_rows 件\n";
for ($i=0; $i<$num_rows; $i++) {
@a = $sth->fetchrow_array;
print "id=$a[0], name=$a[1] memo=$a[2] \n";
}
$sth->finish;
$db->disconnect;
$db = DBI->connect('DBI:mysql:LA00000000-abcdefghijkl:mysql504.phy.lolipop.jp', 'LA00000000', '1234567890123456');
$sth = $db->prepare("SELECT id, name, memo FROM list");
$sth->execute;
$num_rows = $sth->rows;
print "該当 $num_rows 件\n";
for ($i=0; $i<$num_rows; $i++) {
@a = $sth->fetchrow_array;
print "id=$a[0], name=$a[1] memo=$a[2] \n";
}
$sth->finish;
$db->disconnect;
お、なんだか自分でも色々できそうな気がしてきたぞ!というところで、おしまい。何かちゃんとしたもの、作ってみて公開するかも。